Data Transfer
Data transfer is essential between operations in a pipeline. In pypz data transfer is possible between operators through so called ports.
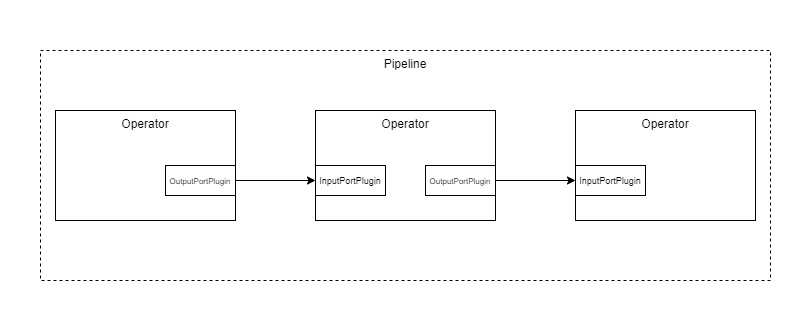
Basic pipeline
Ports
An input and output port in pypz is an actual implementation of the corresponding interfaces:
Inheritance diagram
Basically, you are free to implement any technology behind ports as long as you comply to the interfaces:
Important
Note that although pypz has a lot of builtin guards and trails to ensure execution stability, it does not provide quality guarantees for custom interface implementations i.e., pypz will not take responsibility to any damage caused during execution of a custom port plugin.
Channels
During implementing the data transfer logic behind the port interfaces, you might encounter some challenges, which takes more time to solve or even forces repetitive activities. Some of the challenges are:
connection state management and transfer i.e., ports are aware of other ports’ states
continuous health checks / heartbeats
group handling i.e., if the operator is replicated, the channel gets this information
quality metrics and statistics
…
For that reason pypz offers you an alternative view on how data can be transferred across ports.
Note
The following feature is completely independent from ports, you can consider it as an extension, which you are free to use. However, pypz’s implemented port plugins are based on this feature.
In pypz’s view, each connection between ports can/shall be isolated. Such a connection can be represented as a channel.
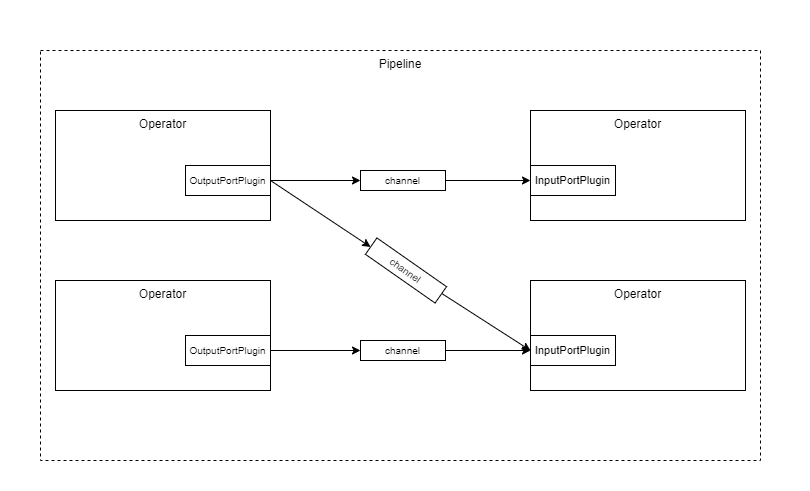
Pipeline with ports and channels
Actually, in the reality the channel is a virtual model, it exists due to the fact, that there is a resource somewhere, where the data is written to and read from. The actual functionality is put into so called channel readers and channel writers.
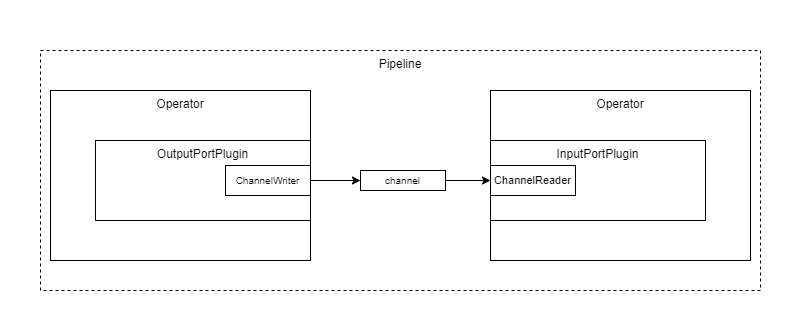
ChannelReader/-Writer
If you want to utilize channels, then you shall implement the abstract methods of the corresponding classes instead of the port interfaces.
pypz.core.channels.io.ChannelReader
pypz.core.channels.io.ChannelWriter
Note
Notice that the abstract methods are protected and shall not be called directly. The channel classes are providing invoker methods that will invoke the protected methods along with other code that abstracts a lot of complexity for you. For more information, check the code.
The question is, how to use the implemented channels. If you think carefully, you will notice that it is always the same pattern:
create the necessary resources
open the channels
eventually wait for other connected channels
start the transmission
finish the transmission
close the channels
clean up resources
To unload you from creating boilerplate code every time you have a new channel implementation, pypz provides an abstract input and output port plugin, which takes care all of these steps, so at the end you just need to provide the channel implementation, everything else will be taken care of.
Note
pypz ships with a channel implementation for Kafka
ChannelInputPort, ChannelOutputPort
This is a builtin implementation of the InputPortPlugin and OutputPortPlugin interface that integrates channels into pypz. It provides all the necessary method calls of the channels to perform data transmission.
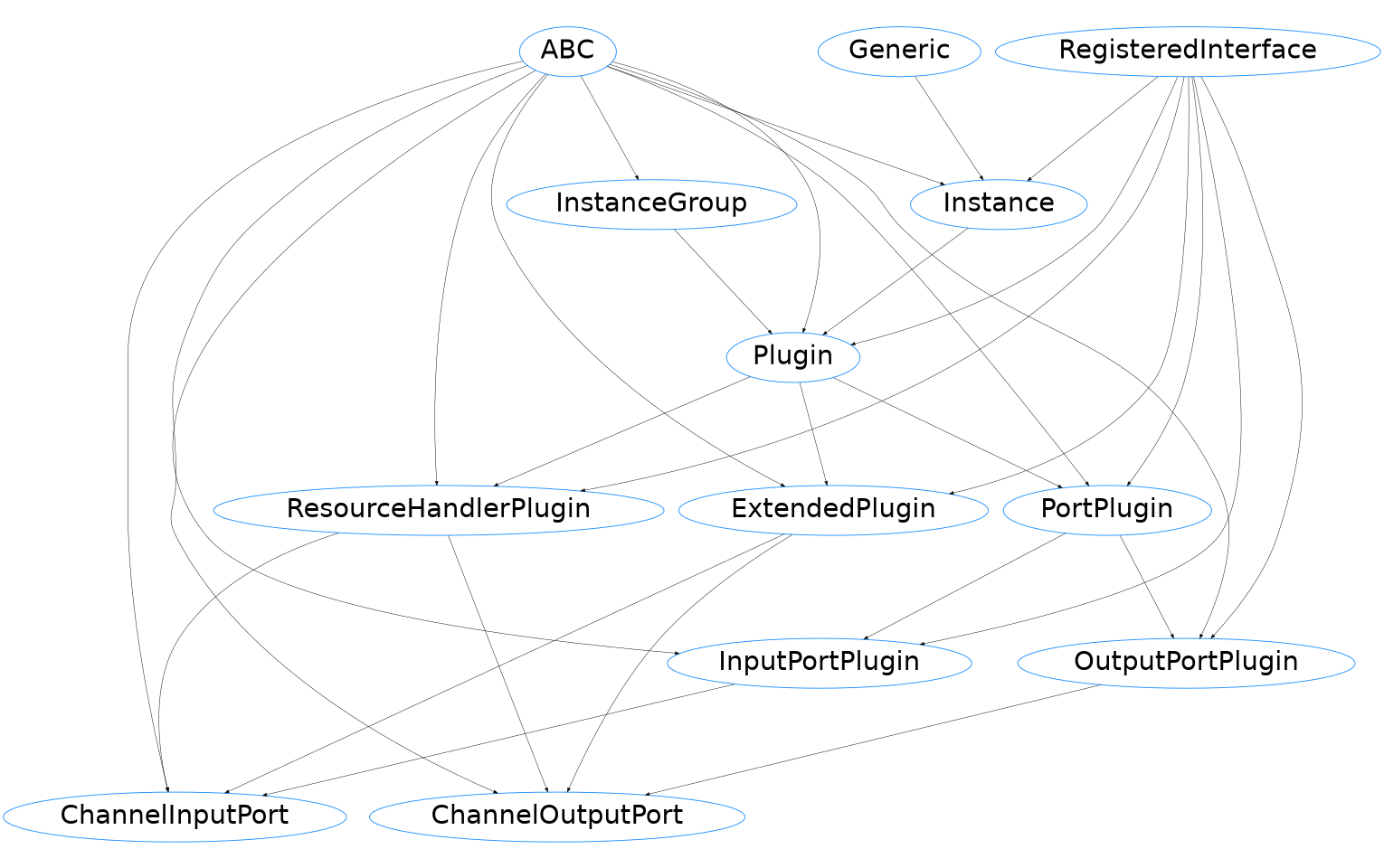
Inheritance diagram
Notice that both plugins are implementing the ResourceHandlerPlugin
interface as well, which allows to create and delete resources for the channels.
Note
Note that it is not mandatory to use this plugin. If you have a better idea, how to integrate channels into pypz, feel free to implement it.
Although ChannelOutputPort and
ChannelInputPort has an N-to-M relation,
there is an N-to-1 relation on channel level
i.e., a ChannelOutputPort will create as many
ChannelWriter as many
ChannelInputPort
is connected, but the ChannelInputPort creates only one
ChannelReader.
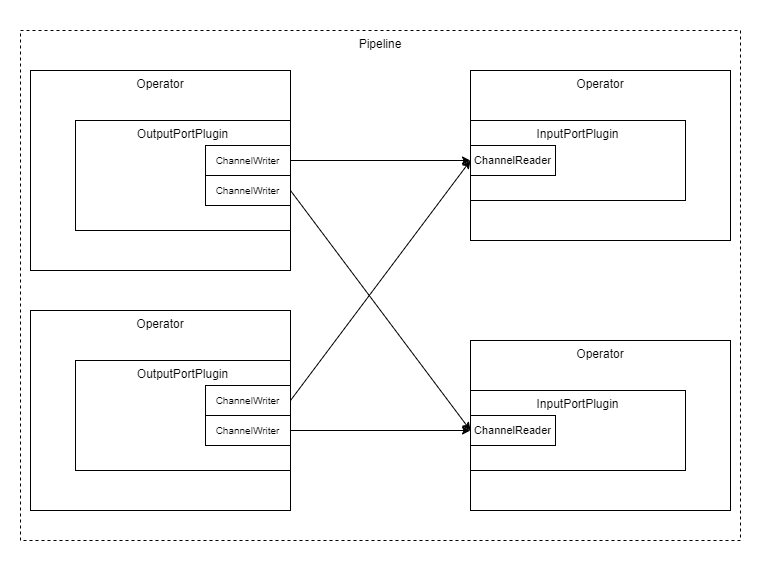
ChannelWriter-ChannelReader N-1
The reason is that from ChannelInputPort
perspective you have certain expectations w.r.t. records to receive, so there
is no reason to create different ChannelReader entities,
because all the ChannelWriter shall meet your expectations.
In other words, by invoking the pypz.abstracts.channel_ports.ChannelInputPort.retrieve() method,
you will then get all the records from all the outputs anyhow.
Note
This design decision requests you to manually care for record ordering, if you have such a requirement.
Further information:
if an operator is replicated, then it forms an instance group; only group principals can manage resources, replicas cannot
in case of error resources WILL NOT be deleted, this feature ensures that in case the principal instance crashes, it can restart and continue the work without deleting the resources containing the already transmitted records
in shutdown phase both resource deletion and channel closing is attempted for each channel writers and readers at least once
Expected Parameters
channelLocation, location of the channel resource
channelConfig, configuration of the channel as dictionary (default: {})
sequentialModeEnabled, if set to True, then this port will wait with the processing start until all the connected output ports are finished (default: False)
portOpenTimeoutMs, specifies, how long the port shall wait for incoming connections; 0 means no timeout (default: 0)
syncConnectionsOpen, if set to True, the port will wait for every expected output ports to be connected (default: False)
channelLocation, location of the channel resource
channelConfig, configuration of the channel as dictionary (default: {})
portOpenTimeoutMs, specifies, how long the port shall wait for incoming connections; 0 means no timeout (default: 0)
Note
As mentioned, the parameter “channelConfig” is a dictionary. The base channel class is providing the following parameters:
metricsEnabled, if set to True, then some metrics will be calculated and logged (default: False)
logLevel, specifies the log level for the channel (default: “DEBUG”)
Different channel implementations may require additional configuration. Example set channel configuration parameter:
plugin.set_parameter("channelConfig", {"metricsEnabled": True})
Circular Data Transfer (Cyclic Pipelines)
It is possible to define circular data transfer by connecting the corresponding ports.
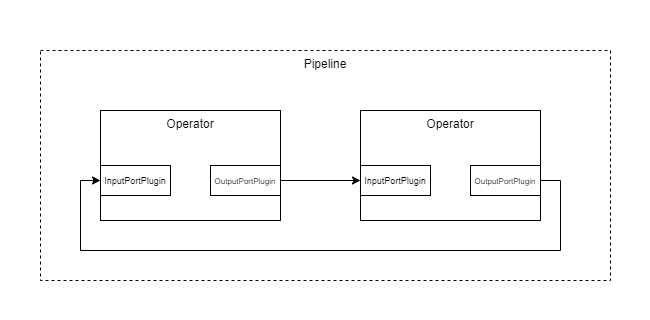
To understand the implications of such a case, you need to understand the transfer control behind the scenes. As discussed above, the channels are coordinating themselves through control signals. For instance, the channels are sending state information to their counterparts such as open, started, stopped, closed. Every channel in each input ports are staying alive and waiting until the connected output channel is healthy and not closed. A channel will be closed, once the operator transits into the ‘shutdown’ state. Usually an operator will transit into the shutdown state, if all input connections are closed. In an acyclic case, this makes sure that once the operator w/o input port is finished, every succeeding operator in the pipeline can terminate.
Important
As you might notice, in a cyclic pipeline no operator is transiting into shutdown, at least not automatically. In a circular case you ALWAYS need to make sure, you handle termination manually, otherwise you will have an infinitely running pipeline.